pandaocr是一款十分好用的开源ocr软件。多种识别功能等着你来使用,支持中英双语同步翻译识别。简单易上手的操作会给呢的识别体验带来极大的便捷,还不是很了解如何使用pandaocr来识别pdf的小伙伴们,下面将会为大家带来详细的教程。

pandaocr识别pdf教程
这款软件是无法进行直接识别pdf文件的,不过我们可以使用其他的方法来进行。
首先打开你所想要识别的pdf文件,这时候有两种方法进行识别,其一:使用电脑自带的截图功能,将整页pdf进行截图,之后上传图片进行识别。其二:利用pandaocr的截图功能进行截图识别。具体的操作请看下方。
图片识别
点击右边框中的图片识别,将刚刚你所进行截取的pdf文件图片,将它导入到软件中。

软件会为你自动的进行识别截图,等待一会后在软软件的右边就会显示出识别后的内容,同时还会进行英语或者是中文的对应翻译。
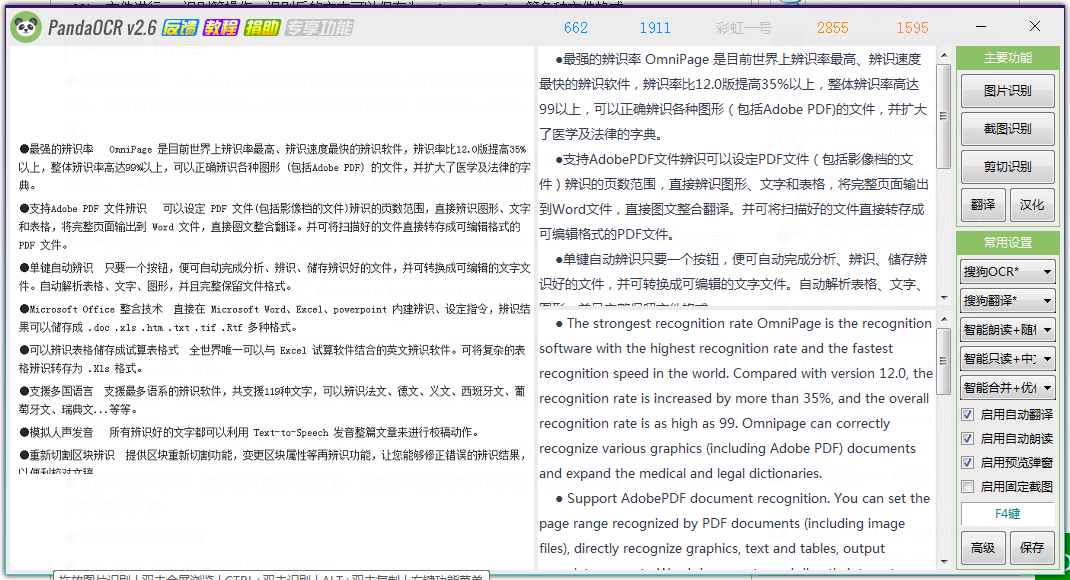
截图识别
首先打开你所需要进行识别的pdf文件。
之后在pandaocr中选择截图识别,点击后开始对pdf文件进行截图。确认截图的部分后导入到软件中。

软件会自动对截图进行识别,同图片识别一样,右边会显示出识别的结果和不同语言的翻译。
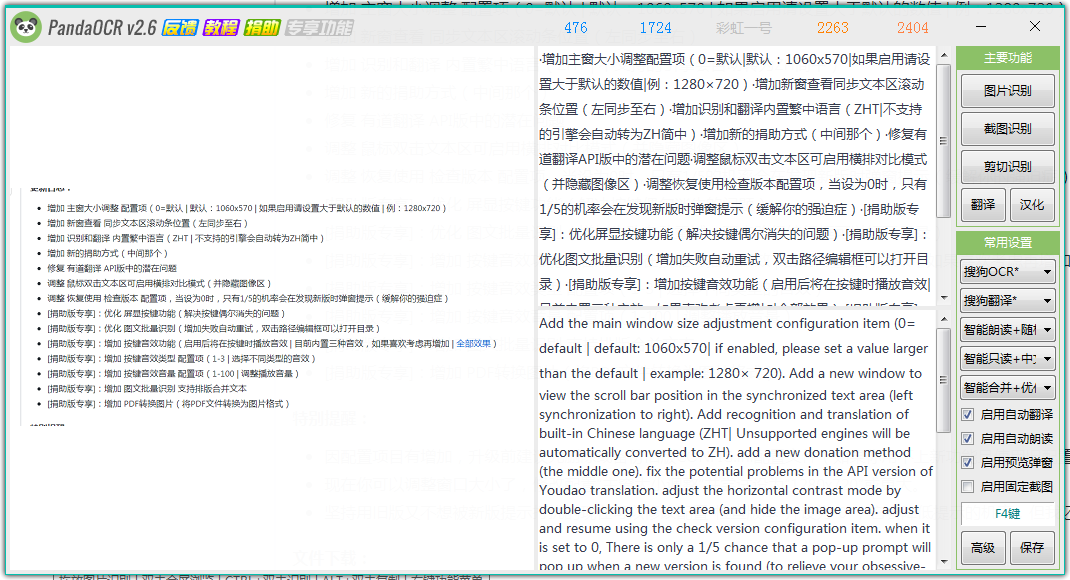
通过上面这两种方法我们就可以去识别pdf文件中的文字了,虽然操作有点繁琐,但是识别的精准度是十分高的。如果你是在是觉得很麻烦,可以去下载专门编辑pdf文件的软件来进行编辑。